
Long Term Security Research Approaches


Much of the time people engage in short term security testing such as penetration tests, vulnerability assessments, code reviews, etc. Often these are 1-2 weeks with some period for reporting. The approach to conducting these sorts of projects typically includes the following types of steps:
- Heavy reliance on automated tools such as scanners.
- Focus on low hanging fruit and quick wins.
- Testing of customer provided environment.
- Quick summarizing knowledge of the target.
- Two types of attack surfaces stand out: remote attacks against listening services, web applications, or phishing and insider attacks.
There are downsides to this approach. The amount of coverage of the target that can be done is limited. The depth of understanding of the target by the analyst is also limited. All of the potential attack surfaces typically can't be covered. The possibility of creative discovery of novel attack classes or paths is greatly reduced.
What is more rare is the application of long term security research against a target. This is the area I focus on most often these days, with projects lasting between 3 - 6 months or in some cases multiple years. One of the goals of this approach is to gain as deep and as broad an understanding of the target technology as possible. This enables a closer relationship with the customer; you understand their business and technology needs, and over time you get to know the customer's challenges in ways you cannot with a 1-2 week test.
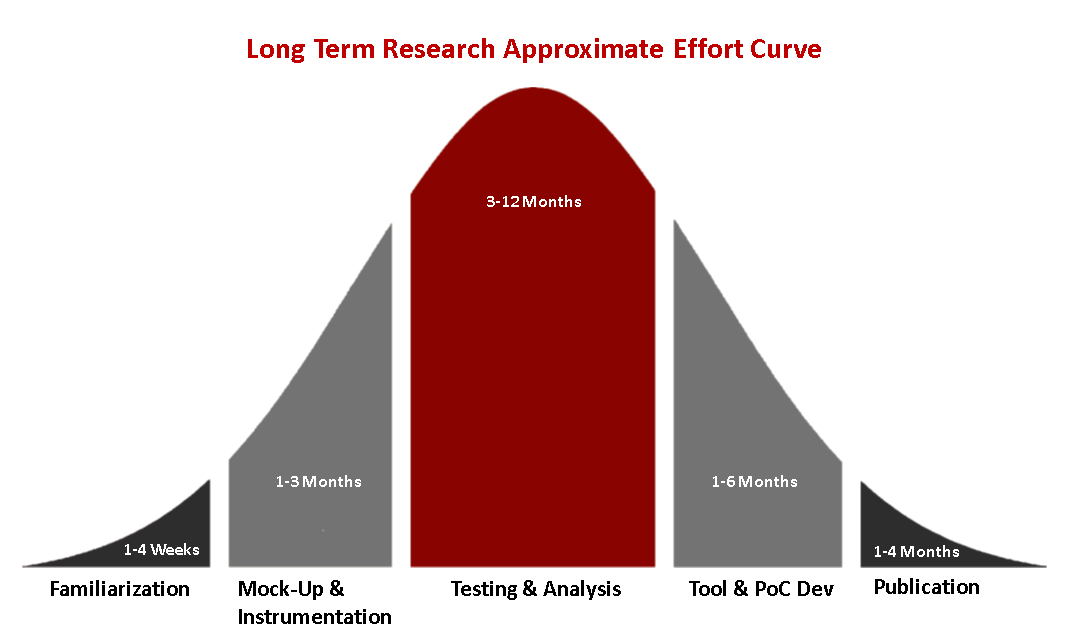
With long term research you can develop complex frameworks and toolsets which can be used operationally, or for automating testing as a part of the SDLC, etc. This requires a different approach consisting of:
- Thorough review of available documentation. [~1 week]
- Target Cataloging. If hardware, take high resolution photographs of all sides of the device, inside and out, and closeups of all important components such as processors, eeproms, flash chips, etc. Look up the components, obtain Data Sheets, and review. If software, walk through and screenshot every possible action.
- Training on the target technology if available. (Otherwise look for public youtube videos, talks, slides, forum posts, github repos) [1-2 weeks]
- Mock-up of the target and typical environment. If its possible to get the target's source and build / compile it, that's a good way to learn about things such as build flags, compile security, etc. If the target requires a webserver and/or a database server that should be built and configured as well to gain an understanding of potential setup mistakes. One thing to consider is having the ability to rapidly deploy mock up environments in an automated way that conform to the standards of the real world target. (STIGs, USGCB, etc.) If its a hardware device maybe it depends on other devices or infrastructure. That should be setup as well. [Could take several weeks or months depending on the complexity of the target. Extensive notes should be taken with an eye for potential attack paths]
- Instrumentation. As extensive as possible. [~2 weeks, maybe longer] Examples include:
- Full packet capture. Every packet going in and out of the target should be saved and analyzed. Often I'll have different captures such as one for device / application start up, one for idle, one while under scan, one during normal use, one during attack attempts, etc.
- File System Monitoring. This might be using something like sysinternals on Windows, auditd on *nix/osx, or even something like Encase. The purpose of this is to see every process that reads, writes, modifies, or deletes anything on the filesystem.
- Registry monitoring (if Windows). Same as file system but for the registry. We want to know if keys are created, values changed, what the permissions are, if a target relies on configuration parameters in the registry that can be modified, etc.
- Process table monitoring. Things to understand are process permissions, threads, subprocesses, inter-process communication, if the process kills another process or has a watchdog, etc.
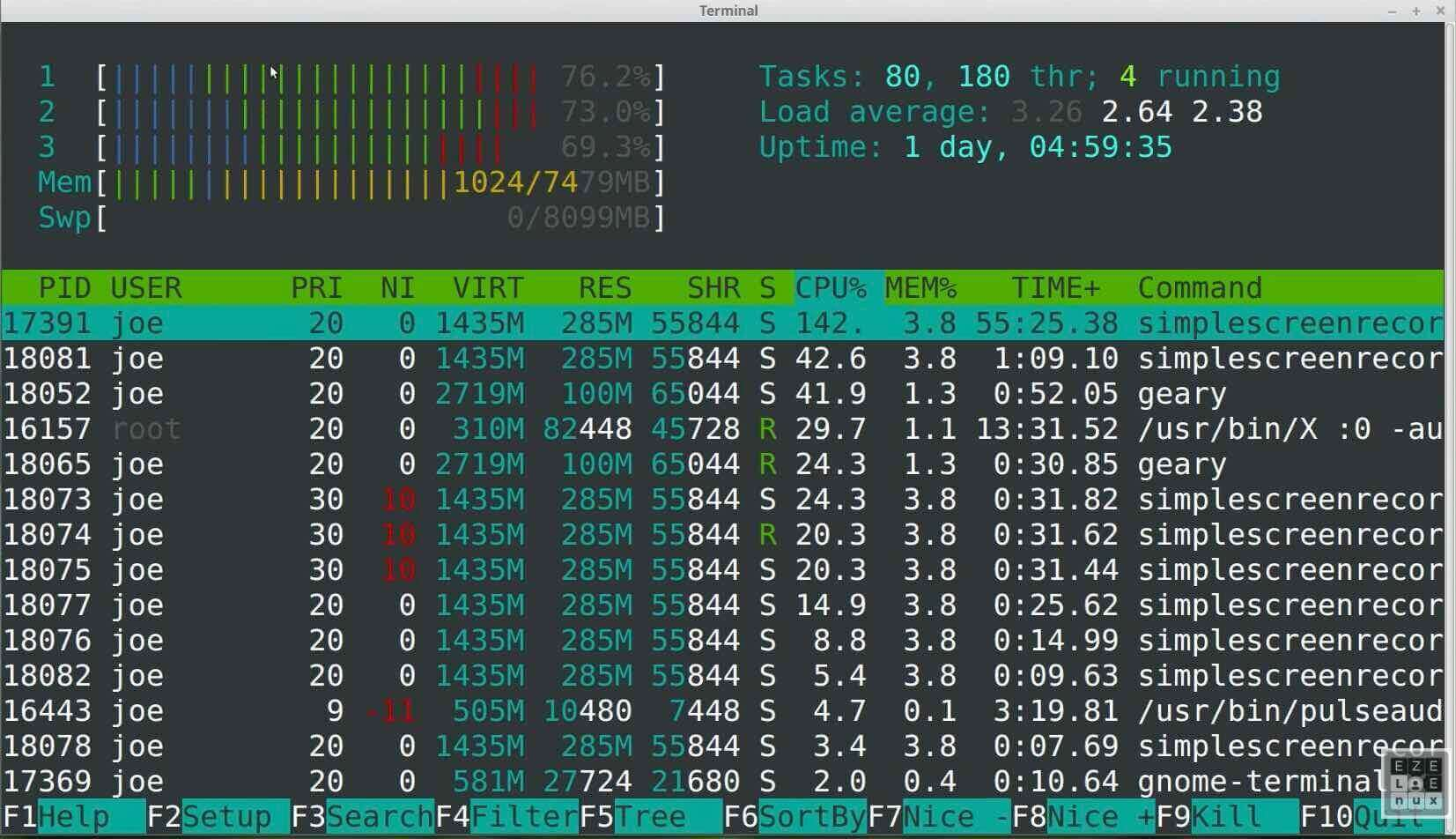
- Memory. Full dumps of the system (or virtual memory files if its a VM), dumps of the process itself, etc. can contain dynamic strings, secrets, or other useful information not easily obtained statically.
- Debugging. It is very useful to run software targets in a debugger such as WinDBG, GDB, x64dbg, Android Studio, Visual Studio, etc. or even remote kernel debugging with IDA Pro. Set breakpoints on useful functions such as string handling, de-obfuscation, network, etc. and you can monitor in real time what the target is doing.
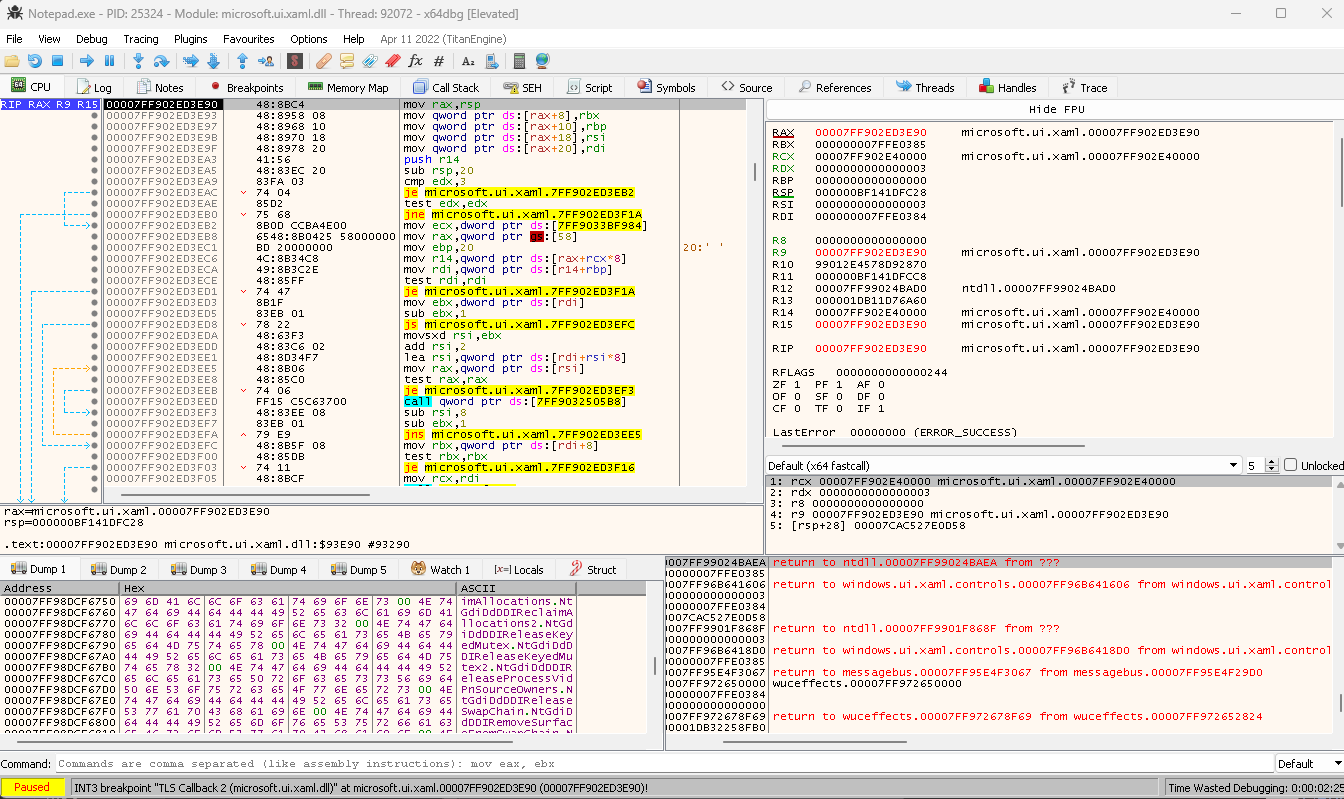
- MITM. Many targets communicate over SSL/TLS and this traffic needs to be monitored. This might require the installation of a custom certificate, cert-depinning, the modification of an APK, the use of a proxy such as BurpSuite, etc. This can take quite a while to setup or need larger external resources. For example, when I was analyzing TikTok I had to spin up a very large AWS EC2 compute node in order to have the resources necessary to de-pin the cert for the TikTok APK.
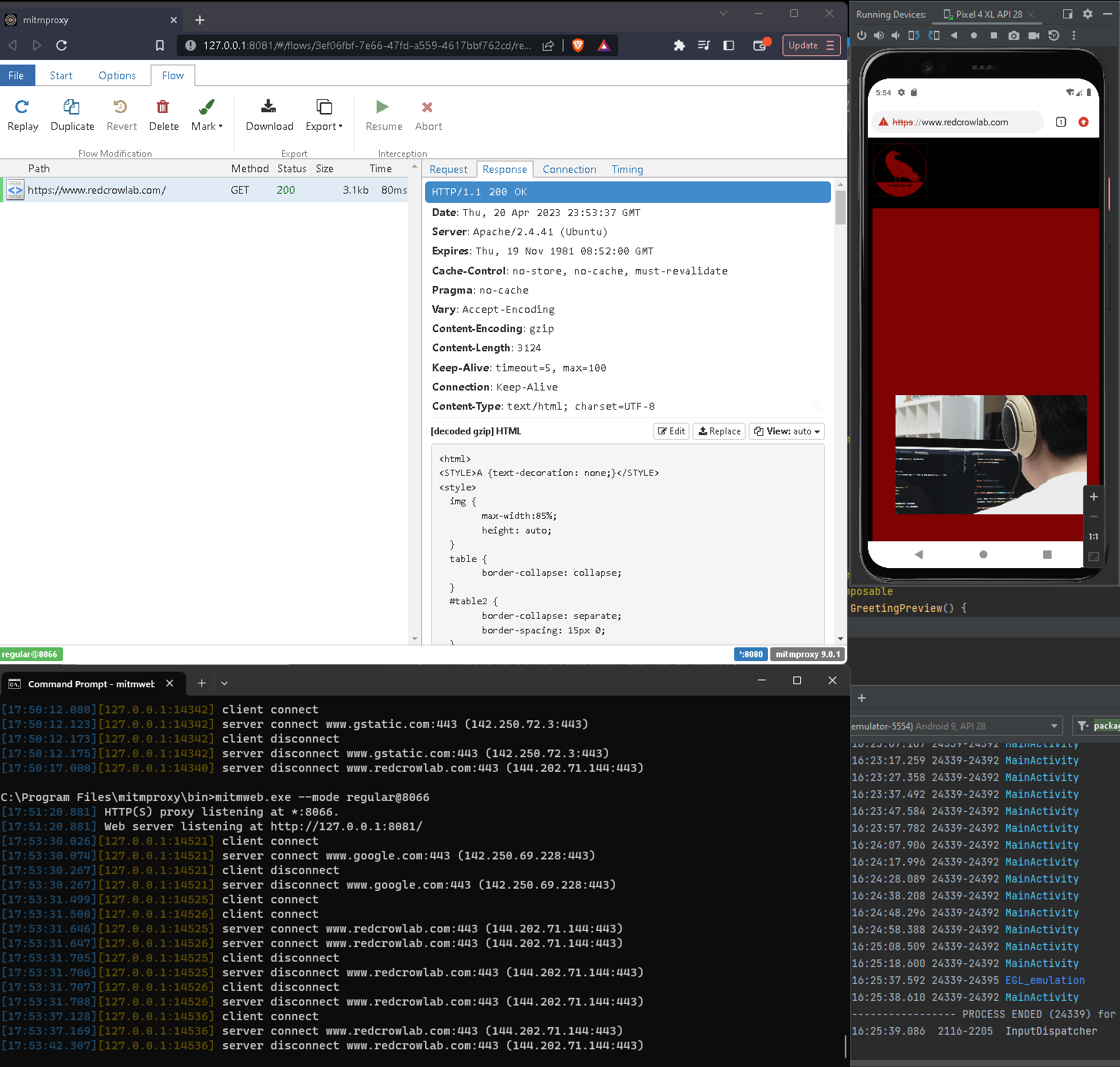
- API Logging. Tracking API calls and function parameters as a program executes. Tools like strace, Logcat, logger.exe, etc. can be used to accomplish this.
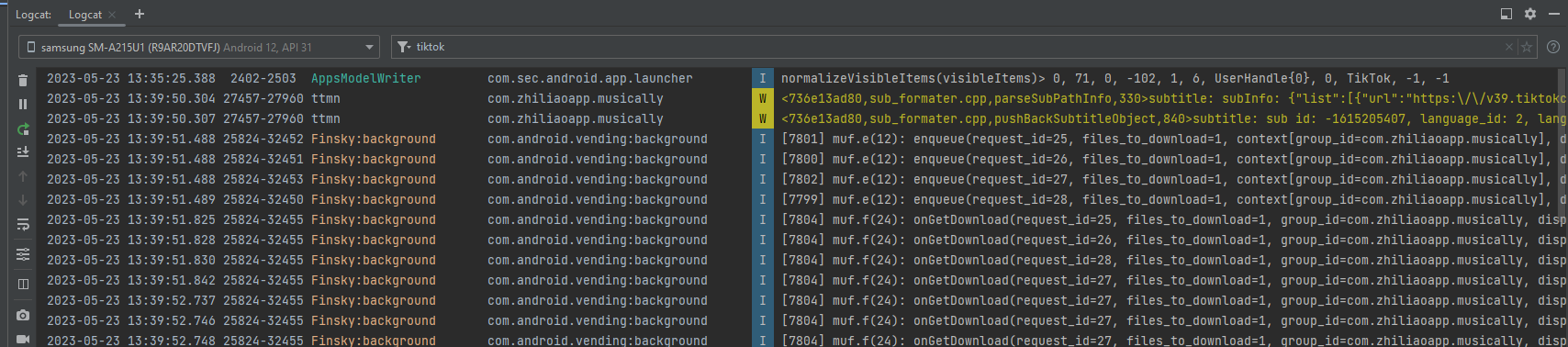
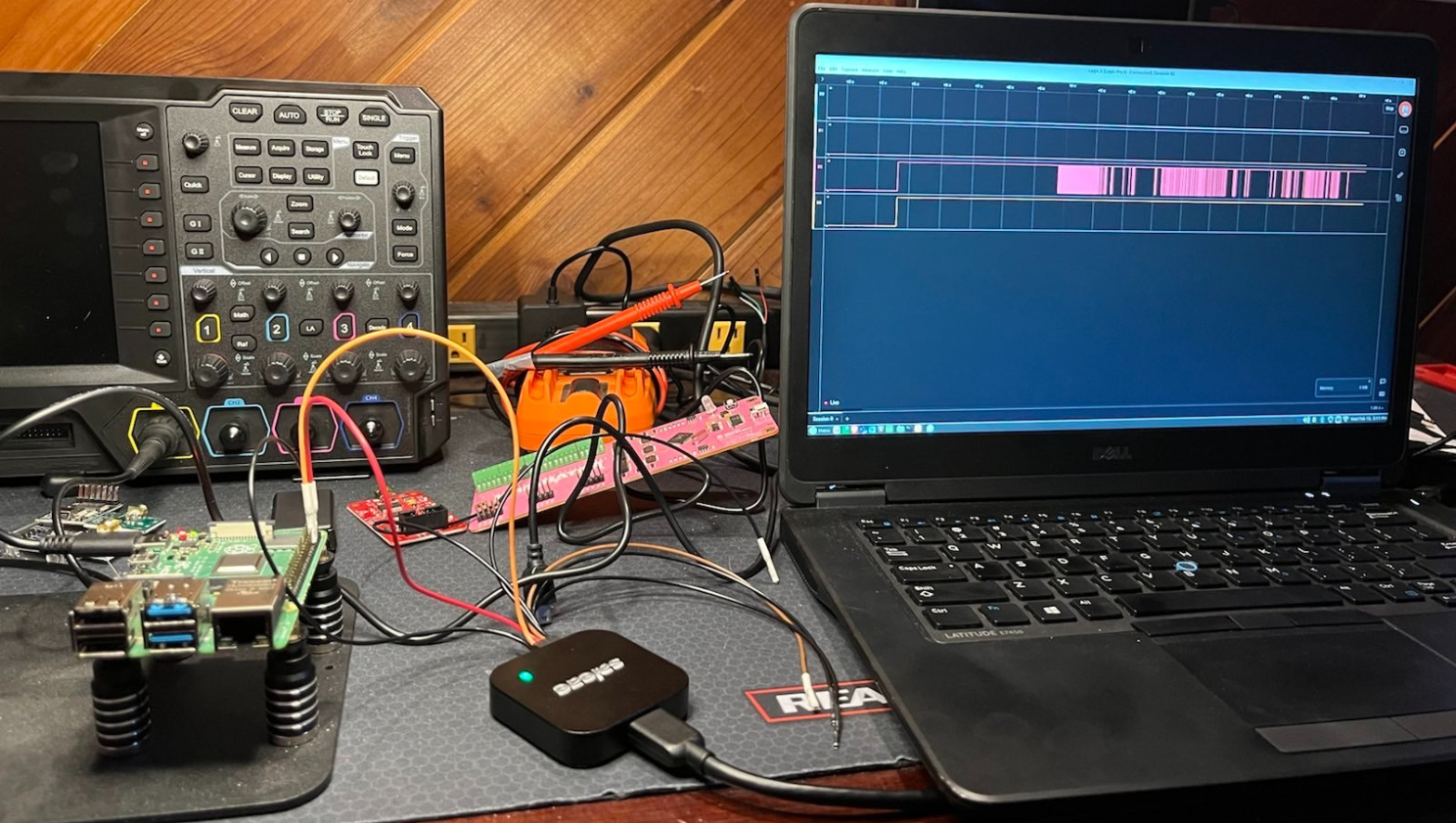
- Hardware Instrumentation. This could be an oscilloscope capturing signals and waveforms, a multimeter monitoring voltages, logic analyzers, or other bench testing devices. Monitoring the device with a spectrum analyzer while in a Faraday cage, or various other RF monitoring tools such as Near Field Probes, Flipper Zero's, etc. can help you understand if the target emanates any useful signals that can be captured, repeated, or that leak useful information.
6. Baseline Testing. If testing software, there is a series of baseline tests that are useful. The focus of this testing is primarily on characterizing the target software as installed. One of the tools RC has released to collect some of this type of information is rcFileScan (https://github.com/redcrowlab/rcFileScan). [Usually can be done in a couple of days or less.] The types of things that get tested in this phase are:
- File Permissions. The EXEs, DLLs, and other associated files are checked for file permissions to see if there are opportunities for replacement, modification, removal, etc.
- Registry Permissions. Registry keys are checked in the same way as files to verify if they are secured correctly.
- Service Permissions. On Windows, many applications install services so that the application stays resident, runs on startup, etc. There are permissions associated with these services which need to be checked to prevent privilege escalations, code execution, etc.
- Binary Security Flags. These are checks for things like ASLR, DEP, NX, etc. This tells you how likely it is a program is susceptible to memory corruption issues (or how hard it will be to exploit if it is).
- General File Characteristics Collection. At RC we like to build databases of targets where we collect as much information about every file as possible. Similar to a malware database, this allows us to cross-reference files, developers, changes over time, binary diff patches to look for vulnerabilities. etc.
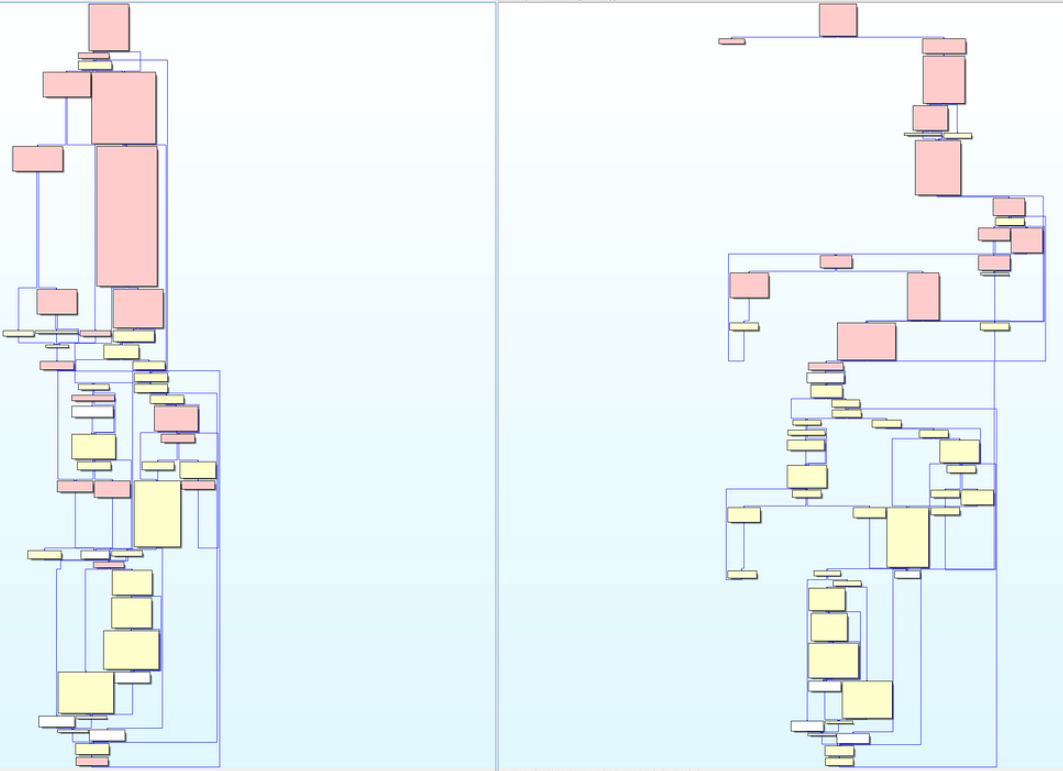
7. Static Reverse Engineering. This is the process of disassembly target binaries. If we are dealing with hardware we identify chips, dump firmware, extract firmware, and disassemble binaries, etc. If we are dealing with a software product we look at binary dependencies, disassemble it in tools like IDA Pro, Ghidra, radare2, etc. and try to identify all of the functions, look for user controlled data, trace this data as it flows through the program, review call graphs, etc. We build an internal knowledge base that multiple analysts can draw on while doing research. This becomes especially valuable when we develop a long term relationship with the customer. Sometimes we end up doing work on multiple versions of a product across many years. Having a knowledge base to refer back to in this case is invaluable. [Timeframe on the order of months]
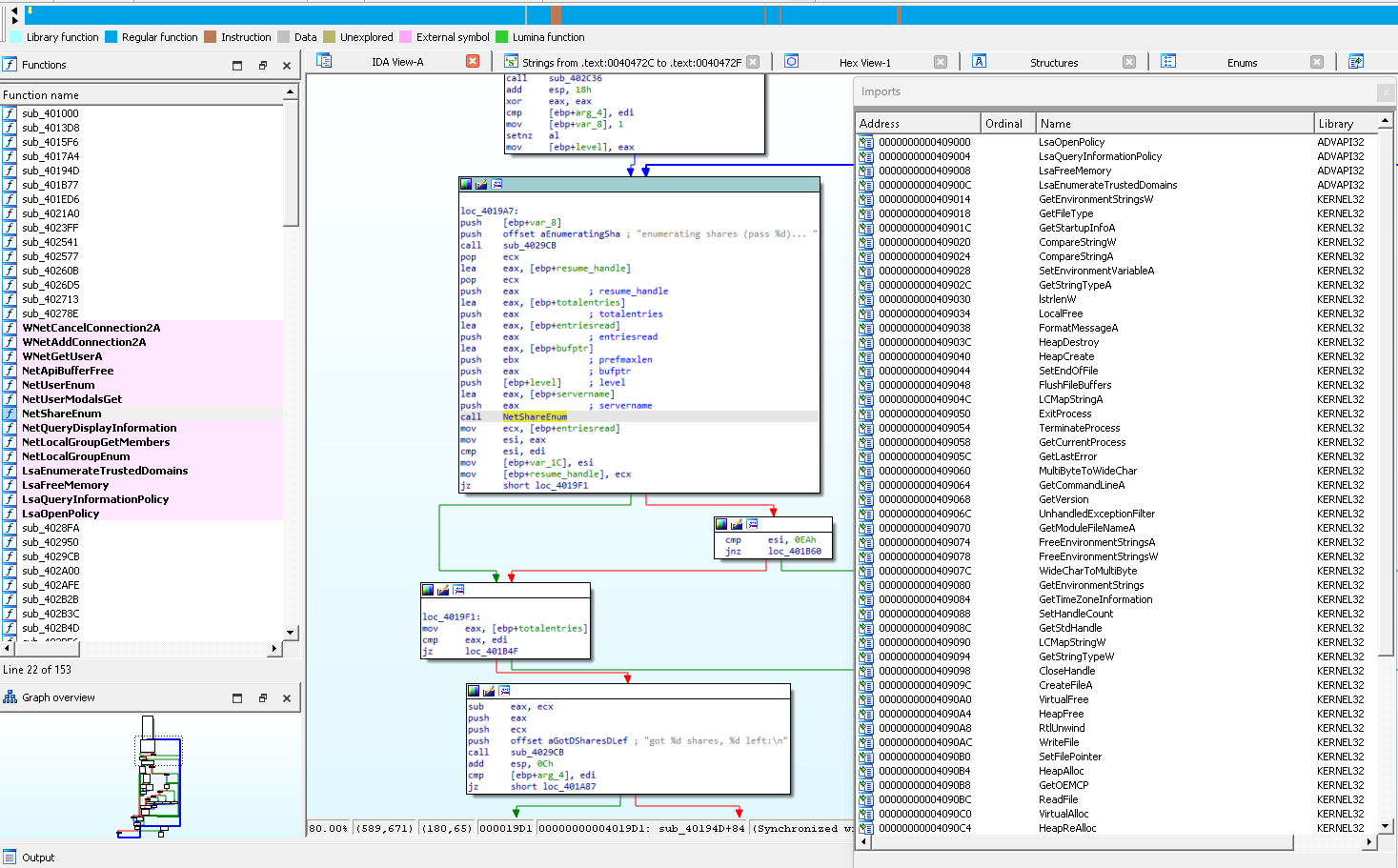
8. Dynamic Testing. Often what we will do is build an instrumented environment that is quick and easy to reset and then do tens or hundreds of runs of the target in different scenarios, walking through every possible use case as well as many different attack approaches. All of the instrumentation data is then mined for potential vulnerabilities and attack paths.
9. Fault Injection. Also known as fuzzing, fault injection is a massive topic, too big to cover here. In summary the idea is to fire all sorts of data, structured, unstructured, encoded, etc. at the user inputs of a target in an effort to cause a crash or other unexpected behavior. This might be a listening network port, a web form parameter, an API, etc. Again, all of these results are stored and data mined much like in previous steps. [Weeks or months depending on the complexity of the target]
10. Proof of Concept & Tool Development. All along this process we often build tools to help us automate steps, data mine instrumentation results, demonstrate vulnerabilities by exploitation, create an APT style set of actions for testing and training detection teams, generation of IOCs, etc. There is a lot of value in this aspect of the research and this really helps not only in gaining an understanding of the target but also in demonstrating and providing evidence to the customer regarding risk, impact, and recommendations.
11. Knowledge Base Construction. When doing long term research having a formalized approach, a process for note taking, long term information storage, and a set of tools to enable collaboration between analysts is imperative. If you didn't document it, you didn't do it. We use tools such as:
- Code Repos - For internal tool and POC storage and development. (GitLab, GitHub)
- KanBan Boards - For planning research steps and tasks and tracking progress. (GitLab, Jira, etc.)
- Note Taking - Notes often get converted or incorporated into more formalized documentation but all the analysts have systems for recording and shareing notes. (Obsidian Notes, OneNote, Sublime.)
- Collaboration Tools - For storing images, notes, testing results, How-Tos, important graphs, screenshots, etc. (Confluence, BookStack, GoogleDocs)
12. Publishing. At a certain point a determination is made regarding publishing the research. This depends a lot on if this is self directed research, research sponsored by a customer, a government entity, etc. This can take many forms:
- A comprehensive report with appendixes to the customer.
- A sanitized white paper.
- A blog or LinkedIn Post.
- A conference presentation.
- Public code repo release of PoCs or toolsets.
- Twitter (X) posts, Youtube videos, other social media releases.
You can find some of Red Crow's releases on our GitHub or the research section of our website as well as our blog.
- Research Papers: https://redcrowlab.com/papers.php
- Git Repo: https://github.com/redcrowlab
- Blog: https://blog.redcrowlab.com/
Thanks for reading,
A.